中國展會資源整合平臺——八方資源網展會黃頁全解析

隨著中國會展經濟的蓬勃發展,展會已成為企業拓展市場、品牌曝光和業務合作的重要渠道。八方資源網展會黃頁作為國內專業的展會信息發布平臺,為展會公司、參展廠家及廣告商提供了全面的資源對接服務。
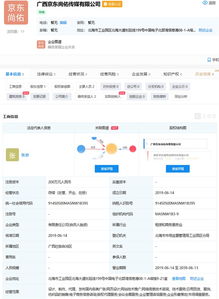
在八方資源網展會黃頁中,用戶可以便捷地查詢到全國各類展會信息,包括行業展覽會、貿易洽談會、技術交流會等。平臺通過智能分類和地域篩選功能,幫助用戶快速定位目標展會,涵蓋機械、電子、食品、服裝等多個領域。對于展會公司和廠家而言,黃頁不僅是信息發布的窗口,更是商業機會的源泉。企業可通過發布展會預告、展位招商信息,吸引潛在客戶和合作伙伴。
八方資源網支持廣告發布服務,企業可利用平臺投放國內各類廣告,從線上推廣到線下展會聯動,形成全方位的營銷矩陣。通過整合資源,平臺幫助企業降低參展成本,提高參展效率,推動產業鏈上下游的協同發展。
八方資源網展會黃頁以其實用性和專業性,成為中國會展行業不可或缺的助手,助力企業抓住商機,實現可持續增長。
如若轉載,請注明出處:http://m.dhtay.cn/product/25.html
更新時間:2026-06-19 07:13:18