林奇退任南京奇酷網絡科技公司,持股比例降至50%
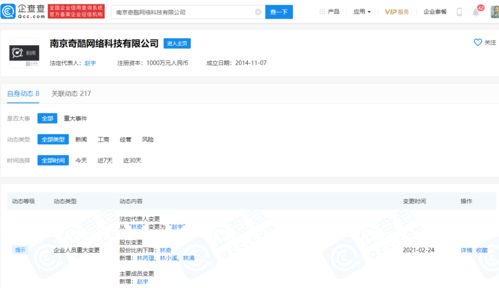
南京奇酷網絡科技有限公司發生重要工商變更,原法定代表人、執行董事林奇已正式退任,其在該公司的持股比例也同步調整至50%。這一變動引起了行業內外對該公司未來戰略方向與業務布局的廣泛關注。
南京奇酷網絡科技有限公司作為一家專注于數字營銷與廣告服務的企業,其核心業務涵蓋國內各類廣告的策劃、發布與推廣。林奇作為公司的創始人及長期以來的核心管理者,其退任無疑標志著公司進入了一個新的發展階段。盡管持股比例有所降低,但林奇仍保留50%的股權,表明其將繼續以重要股東的身份參與公司治理,或轉向更為宏觀的戰略指導角色。
此次調整可能基于多方面的考量。一方面,隨著市場競爭加劇與行業數字化轉型的深入,公司或許正尋求更專業化的管理團隊,以優化運營效率并拓展新興廣告業務領域,如程序化購買、社交媒體營銷或短視頻內容廣告等。另一方面,股權結構的變動也可能為引入新的戰略投資者或合作伙伴鋪平道路,從而增強公司的資本實力與市場競爭力。
對于國內廣告行業而言,南京奇酷網絡科技的此番變動或反映出行業內部資源整合與人才流動的常態趨勢。在廣告發布業務日趨規范、技術驅動日益凸顯的背景下,企業通過調整治理結構來適應變化,有助于提升服務品質與客戶滿意度,進一步鞏固其在廣告市場的地位。
南京奇酷網絡科技是否會延續其在傳統廣告發布領域的優勢,抑或轉向創新廣告模式的探索,仍有待觀察。但可以確定的是,在林奇持股比例保持半數的前提下,公司的戰略決策仍將深受其影響,而新的管理團隊能否帶領公司在“廣告+”生態中開辟新局,將成為行業關注的焦點。
如若轉載,請注明出處:http://m.dhtay.cn/product/66.html
更新時間:2026-04-14 19:18:55