不只制片人 何雯娜未婚夫梁超,廣告行業低調布局者
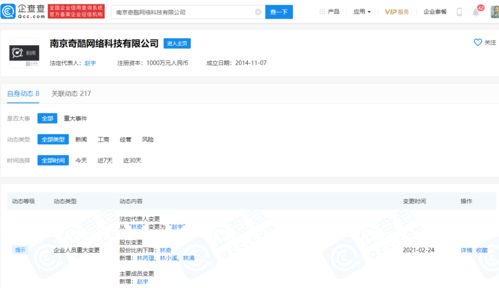
奧運冠軍何雯娜與其未婚夫、知名制片人梁超的婚訊備受關注。除了在影視制作領域廣為人知的身份外,梁超在商業領域的布局同樣引人注目。據公開信息顯示,梁超名下或關聯的公司數量達7家,這些公司業務范圍廣泛覆蓋廣告行業,專業從事國內各類廣告的發布與運營。
作為一位資深的制片人,梁超在影視內容創作方面有著豐富的經驗和成功案例。其商業版圖并未局限于文娛產業。通過關聯的這7家公司,梁超在廣告市場進行了多元化且深入的戰略布局。這些公司可能涉足廣告策劃、媒介代理、數字營銷、戶外廣告發布等多個細分領域,形成了一個協同運作的商業網絡。這不僅體現了其敏銳的商業嗅覺,也展現了其在文化產業與商業市場之間搭建橋梁的能力。
廣告行業作為市場經濟的重要環節,與影視文娛產業有著天然的緊密聯系。梁超的跨界經營,或許正是利用其在內容創作和資源整合方面的優勢,將創意與商業進行有效結合。這種“內容+廣告”的聯動模式,在當前的媒體環境下具有顯著的發展潛力。
值得注意的是,梁超的商業運作顯得頗為低調,較少在公眾視野中大肆宣揚其商業成就,更多精力似乎仍聚焦于內容制作本身。此次因其與何雯娜的婚戀關系而進入大眾討論范疇,其背后的商業版圖才被更多人所了解。這反映出許多文化行業從業者正在以更綜合的視角規劃自身事業,不再單純局限于一個身份或領域。
梁超的例子,可以說是現代文化創意產業人才發展的一個縮影:他們既是內容的創作者,也可能是商業的開拓者。其關聯的廣告公司業務,一方面可能為其影視項目提供營銷支持,形成產業閉環;另一方面,也可能作為獨立業務板塊,在更廣闊的市場中尋求增長。這種多元化的發展策略,在應對市場變化時往往更具韌性。
隨著他與何雯娜即將步入婚姻殿堂,兩人在各自領域——體育與文娛商業——的融合,或許也將帶來新的故事。梁超在廣告行業的這些布局,未來是否會與體育營銷等領域產生更多交集,值得觀察。無論如何,從制片人到多家廣告公司的關聯者,梁超的身份已遠不止于臺前的創作者,更是一位在文化產業生態鏈中深入耕耘的實踐者。
如若轉載,請注明出處:http://m.dhtay.cn/product/68.html
更新時間:2026-04-12 05:29:12